StripeのAPIを利用すれば、請求書PDFのURLを取得できます。この請求書PDFを取得して、S3バケットに保存してみました。
おすすめの方
- Stripeの請求書PDFをS3バケットに保存したい方
Lambdaを作成する
sam init
sam init \
--runtime python3.11 \
--name stripe-pdf-download-test \
--app-template hello-world \
--no-tracing \
--no-application-insights \
--structured-logging \
--package-type ZipSAMテンプレート
S3に対するアクセス権を付与しています。
template.yaml
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: stripe-pdf-download-test
Globals:
Function:
Timeout: 5
LoggingConfig:
LogFormat: JSON
Resources:
HelloWorldFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: hello_world/
Handler: app.lambda_handler
Runtime: python3.11
Architectures:
- x86_64
Policies:
- arn:aws:iam::aws:policy/AmazonS3FullAccess
Events:
HelloWorld:
Type: Api
Properties:
Path: /hello
Method: get
HelloWorldFunctionLogGroup:
Type: AWS::Logs::LogGroup
Properties:
LogGroupName: !Sub /aws/lambda/${HelloWorldFunction}
Outputs:
HelloWorldApi:
Value: !Sub "https://${ServerlessRestApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/hello/"requirements.txt
2つのライブラリを利用します。
requirements.txt
requests
stripeLambdaコード
invoice情報を取得してPDFのURLを把握します。次にPDF情報を取得して、S3バケットに格納します。
app.py
import json
import requests
import stripe
import boto3
# テスト用のため、APIキーをハードコーディングしています。
# パラメータストア(Secure String)などから取得してください。
stripe.api_key = "sk_test123"
s3 = boto3.client("s3")
S3_BUCKET_NAME = "xxx"
INVOICD_ID = "in_aaa"
def lambda_handler(event, context):
invoice = stripe.Invoice.retrieve(INVOICD_ID)
resp = requests.get(invoice["invoice_pdf"])
s3.put_object(
Bucket=S3_BUCKET_NAME,
Key=f"{INVOICD_ID}.pdf",
Body=resp.content,
ContentType="application/pdf",
)
return {
"statusCode": 200,
"body": json.dumps(
{
"message": "hello world",
}
),
}デプロイ
sam build
sam deploy \
--guided \
--region ap-northeast-1 \
--stack-name stripe-pdf-download-test-stackLambdaを実行すると、S3バケットに請求書PDFが保存された
Lambdaを実行すると、S3バケットに請求書PDFが保存されました。
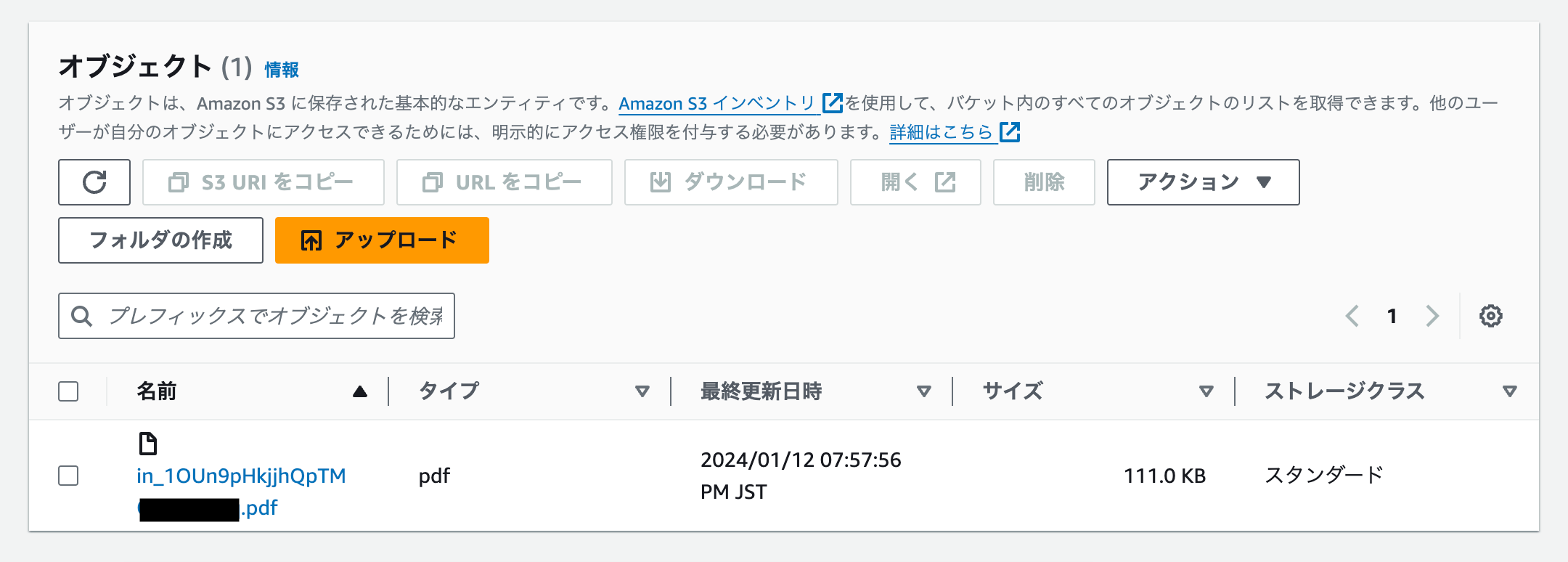
ダウンロードすると、問題なく請求書PDFが閲覧できました。

 2
2

